Loading data
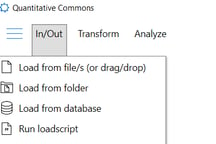
There are multiple options for loading data into Quantitative Commons. From the In/Out menu item, a user can select a file from which to load data, select a folder containing files to load, open the database load interface, or select a load-script to run. Data may also be loaded by dropping files into the data pane or into the dataset view.
Settings for data parsing are found by clicking the blue menu icon in the top left corner of the application window.
Loading data from files
A file selected via the Load from file/s menu item or dropped in the data pane will be loaded into Quantitative Commons, and the contents will be shown in the data pane (if Design mode is activated a maximum of 300 rows are loaded). Supported file types are MS Excel files (.xls, .xlsx, .xlsm), delimited files (.csv, .txt), XML-files (.xml), JSON-files (.json) and MS Word-files (the content of Word-files will not be shown in the data pane, but requires Text extraction tools to be run first).
If a source file does not have a standard suffix (e.g., an XML-file has a file suffix other than .xml), the Associate suffix to file type setting can be used to make sure it is parsed appropriately.
For delimited files, the delimiter used is automatically calculated. Should the result of this calculation be wrong, or if a source file is delimited by a character other than comma, semicolon, colon, tab or pipe, the Verify auto-detected delimiter setting may be activated to prompt manual selection.
Quantitative Commons automatically identifies and corrects non-flat delimited data (f. e. a .csv-file with some header data resulting in a different number of columns for different rows). The Check for non-flat delimited data setting controls the number of rows that are checked for non-flat data. The default is 5.
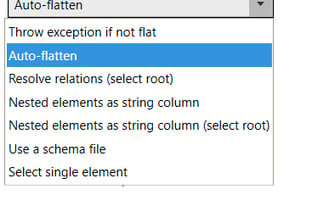
When an XML- or JSON-file is loaded, Quantitative Commons automatically determines whether it has a flat structure, in which case it is loaded in the same way as f. e. a delimited file. If it does not, the file is parsed in accordance with whatever setting is selected in the XML/Json Load method drop down menu. The default method is to Auto-flatten the data, but there are many other options as well (in addition to creating a load script), like pointing to a schema-file or treating nested elements as strings (that can be made tabular and joined with higher level elements via tools).
Loading multiple files
It is quite possible to select or drop multiple files at once, and also to select a folder from which to select all files (including files in sub directories). This may be done for one of two reasons; either the user wants to merge data from the selected files, or to process every selected file using a certain workflow.
To merge files, set the Load multiple files setting to allow input data to be merged. This changes the default setting, which is to clear all loaded data (that has not been transferred to the dataset view, see below) when new data is loaded. There are other ways to merge data as well (see Joining and merging data).
Selecting multiple files without allowing for merging is only meaningful if there is a recognition template that may recognize some or all of the loaded files. If so, all of the loaded files (and each sheet of Excel-files) will be evaluated against existing templates and, if recognized, processed accordingly.
Loading data from databases
The Load from database menu item opens an interface that lets users connect to a database. Supported database types are MS Access, SQL Server, SQLite, MySQL, PostgreSQL, Neo4J and MongoDB. After selecting the database type, enter appropriate credentials (for file databases it is possible to browse for the relevant path). Then select one of the radio buttons Get from table/collection or Get by query to select a table/collection or use a relevant query language (like SQL or Cypher) to fetch data (other options are described under Loading to dataset view below). Then click Continue to load the selected data.
Checking the Save import as-checkbox and supplying a name for the import allows you to repeat the load by selecting it in the Select saved query drop-down list.


Loading to dataset view
The Quantitative Commons data pane always represents data in a tabular manner, with rows and columns. If you want to work with multiple tables in the same session (when you need lookup-data from a different source or if you are working with different tables that are related by foreign keys), you may keep these tables in the dataset view. To create a copy of the current data to the dataset view, click the Create snapshot button in the bottom left part of the screen.
To directly load file data to the dataset view, you may open the view (click the chevron icon in the top left part of the screen) and drop files into it. Excel files with multiple sheets or XML- or JSON-files that are not flat will be split up into multiple tables that may be moved around and, if necessary, joined into new tables.
When loading data from a database, checking the …and send to dataset view checkbox will send the data to the dataset view instead of the main data pane. Choosing the Or send all tables to dataset view radio button will create one table in the dataset view for each table or collection in the source database.
Clicking a table in the dataset view will select it to be in focus in the data pane. Changes are written back to the dataset view-table.


Using load scripts
When loading XML- or JSON-files with known structures, you may create a script to load a specific type of file, allowing for the specific load to be represented by a tool. This is covered in depth in the Extending the functionality section below.
Auto-detecting visualization fields
This setting lets you apply some principles for auto-detecting DateTime and Latitude/Longitude columns for timeline and map visualizations of loaded data, as well as columns containing nodes that may be linked together in a link chart visualization. If these columns are auto-detected, you need not set any parameters to visualize loaded data in any of these manners. Be aware that there may be some performance cost to this setting.