Creating workflows and recognizing data
Workflows are at the heart of Quantitative Commons. Any sequence of actions (operations) carried out by a user can be recorded into a shareable and repeatable workflow. The workflow may be associated to an exact or approximate structure of source data, and run automatically when such data is encountered.
Recording, importing and exporting workflows
To record a workflow, click the Record-button at the top right corner of the application window. Supply a workflow name and click Create new workflow. Now, any operation, including loading new data and running other workflows, will be saved. Recording will continue until you click Stop recording or close the application.
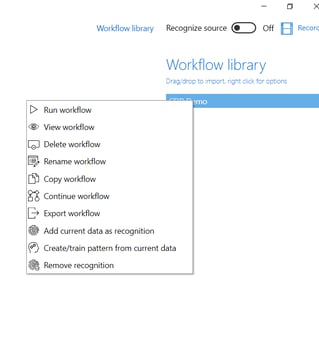
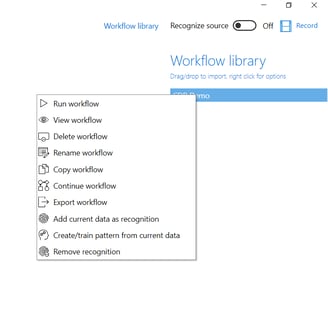
To export a workflow, select the Workflow library to view available workflows. Right click the workflow that you want to export and select Export workflow from the context menu. You may also select View workflow and then select some rows (operations) from the workflow in the workflow window. Right click the selected rows and select Export selected rows as workflow to export those operations as a new workflow.
To import a workflow, simply select the Workflow library and drop a workflow file (suffixed by .qc) in the list of workflows. In the workflow window, you may also drop a workflow into another one to combine them.
Recognizing source data
When you start to record a workflow, if any of the recognition modes at the left side of the application window (=, ≈ or ~) are active, Quantitative Commons will save information about the structure of the source data and associate it with the workflow being recorded. If identical or similar source data is loaded in the future, and if the Recognize source-toggle in the top right of the application window is activated, Quantitative Commons will recognize and suggest or automatically run the associated workflow.
The standard recognition mode (=) and the fuzzy recognition mode (≈) saves information about the header row of the source data, while the data pattern recognition mode (~) saves information about the actual data content of the data source. Multiple modes may be active simultaneously and run in sequence.
Manually or automatically running workflows
To manually run a workflow, select the Workflow library to view available workflows, then right click the workflow that you want to run and select Run workflow from the context menu. You may also select View workflow and either click Run from the workflow window, or click Step to execute the workflow one operation at a time while being able to observe the effects of each operation in the data pane. Another option in the workflow window is to select a row (an operation) from the workflow, right click that row, and select Run to operation from the context menu. This will run the workflow and stop at the selected operation.
Because source data can be recognized automatically, it is also possible to apply workflows to files without using the Quantitative Commons user interface. Right click a file in the file explorer and select Process with Quantitative Commons in the context menu. This will only work if recognition is active as described below.
If the Recognize source-toggle and at least one of the recognition modes are active, Quantitative Commons will try to recognize any data that is loaded and run or suggest an appropriate workflow. The standard recognition mode (=) recognizes an exact header row while the fuzzy recognition mode (≈) recognizes headers that must be present to execute an associated workflow, but disregards superfluous columns and different column order (columns will be appropriately reorganized before executing the workflow). With the fuzzy recognition mode, it is also possible to allow for the spelling of column headers to vary somewhat. This setting is found in the Recognize data settings.
If the first row of the loaded data is not recognized, Quantitative Commons will search for a match for a predefined number of rows below the first one. The default is 10 rows. This may be changed in the Recognize data settings. If a row other than the first one is recognized as a header row, the rows above it may either be kept or automatically deleted. This is also set in the Recognize data settings.
The full auto-mode, represented by the flash-icon at the left side of the application window (also present in the Recognize data settings) controls how workflows associated to recognized source data are executed. If full auto is not active, the recognized workflow will be suggested and a user can select to run it. If full auto mode is active, any workflow associated with a recognized source will be run automatically (and multiple sheets of an Excel-file will be processed one after the other with no prompt for selection).
The data pattern recognition mode (~) is covered in depth in the Advanced recognition section.
Editing workflows
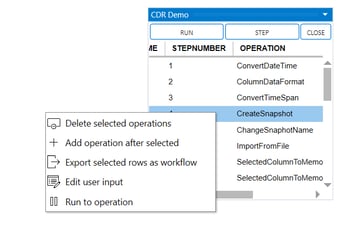
There are multiple ways in which to edit or amend a workflow. Right clicking a workflow lets you Rename or create a Copy of it, or to Continue working on it. The right click context menu also lets you View the workflow, opening the Workflow window with a list of all operations in the workflow.
If you right click one or multiple rows (operations) in the workflow window, a context menu lets you Delete the selected operations or to Add a new operation at the selected step (any operation carried out will be inserted at the selected position of the workflow). You may also Edit user input, letting you change the user control input originally entered when creating the operation represented by the row.
It is also possible to drag a workflow file into the workflow window, dropping it at the position where the operations of the dragged workflow should be inserted into the target workflow.
In addition to editing the actual operations of a workflow, one may also remove or associate new recognition templates to it. Imagine that you have some source data in a different language than you are used to. You may copy your workflow and rename it – f ex. MyWorkflow_NewLanguage. Remove recognition from the copy, load the new language data into the data pane and select Add current data as recognition. You now have a copy of your workflow that recognizes the new language data.
Creating conditions and forking workflows
There is a special category of conditional tools that can be used to make decisions in your workflow. An unlimited number of conditions can be stacked on top of each other, conditioning subsequent operations upon each condition being satisfied. Most of the conditional tools work on a row-by-row basis, making changes only to rows that meet the specified conditions. However, the "If selected column" tool conditions subsequent operations upon column properties.
The running of workflows can also be used as operations in other workflows, simply by selecting and running a workflow while simultaneously recording another one. By conditioning the running of a workflow on some column property being satisfied, you may fork a workflow into several possible paths depending on properties of your data.