Advanced recognition
A central feature of Quantitative Commons is the ability to recognize source data and automatically apply relevant workflows to it when loaded. The standard recognition mode recognizes an exact header row, while the fuzzy recognition mode allows for extra columns, different column order and, if selected, some variation in the spelling of headers. The data pattern recognition mode recognizes the actual data content of a data source. It applies a part rule based, part self-learning algorithm to teach itself to recognize source data loaded into the application. While a very static data source may be recognized after being loaded only once, the more dynamic the source, the more training Quantitative Commons needs to recognize it.
Data pattern recognition can be set either in the main application window of Quantitative Commons, or using the Train recognition section of the settings menu. Using the main window to create a pattern recognition template is a good fit when the columns or fields that are needed to run a workflow are static across data sources, but may vary in header names (f. ex. when you want to recognize a source that may be written in different languages). If columns are dynamic across data sources, the train recognition option is a better fit.
Creating pattern recognition in the main window
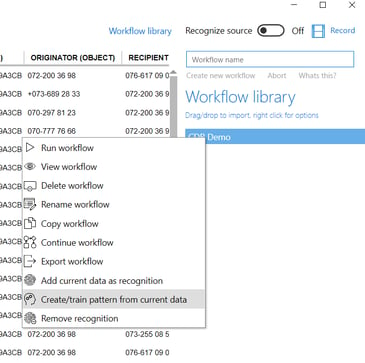
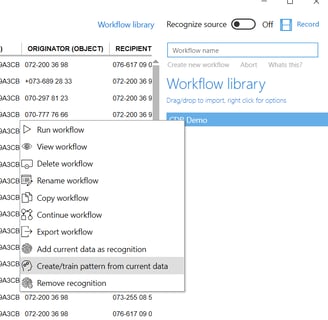
To create a data pattern recognition template in the main window, it is sufficient to make sure that pattern recognition (~) is activated when creating a workflow. The template will be saved with the same name as the workflow. You may also add data pattern recognition to an existing workflow by loading data into the data pane, right clicking the workflow that you want to associate to the pattern of the loaded data, and select Create/train pattern from current data.
You may improve recognition by using Create/train pattern from current data on multiple sources of the type that you want to recognize. When you train Quantitative Commons to recognize a data source, the headers must be identical to the header row used when creating the recognition template. This is necessary for the application to decide whether a guess regarding a column is correct or not, so as to be able to improve its accuracy. When applying the pattern recognition in a non-training situation, the header row has no relevance.
Applying data pattern recognition
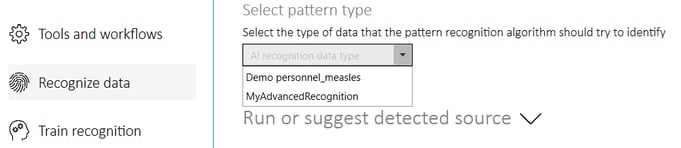
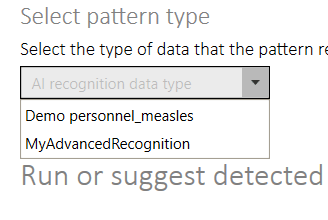
To recognize data patterns when loading new data into Quantitative Commons, the data pattern recognition mode must be active, the Recognize source toggle must be on, and you must also tell Quantitative Commons what type of data it is expected to recognize. To do this, select the Recognize data section of the settings menu, make sure Pattern recognition method is checked, and select the type of data source to expect in the Select pattern type dropdown.
Now, as long as the data pattern recognition mode is active, Quantitative Commons will try to associate the columns of the source data to the columns defined by their data pattern in the selected template.
Creating pattern recognition in Train recognition settings
When using the Train recognition section of the settings menu to create a data pattern recognition template, the source to be recognized is abstract, and does not have to resemble any actual data.
Creating and handling source types
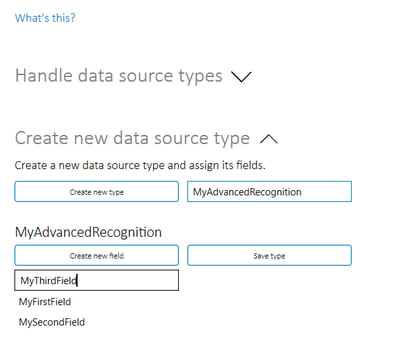
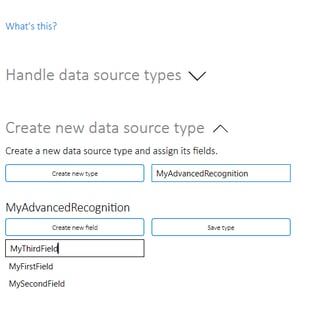
To create a new source type, use the Create new data source type settings in the Train recognition section of the settings menu. This will make visible controls to add the fields that the new abstract data source type should contain. When all fields have been added, click Save type to save the source type.
The Handle data source types settings can be used to delete, export or import templates to/from file.
Mapping data source types to instances
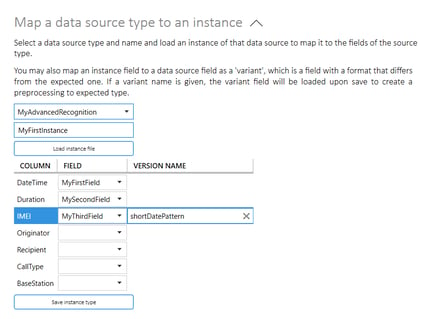
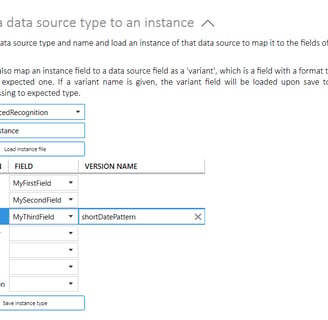
Use the Map a data source type to an instance-settings to map the fields of the abstract source type to the fields of an actual data source containing the data that should be recognized. Select the source type and give your instance a name, then click Load instance file. You can now map each of the fields or columns in the instance file to the fields of the abstract data source.
If you expect a field to have a different representation in different source instances (f. ex. DateTime values expressed with different patterns in different sources), you may give your field a version name. When all relevant fields have been mapped, click Save instance type. Any field that has been given a version name will appear in the main data pane, the recording icon will be visible in the top right corner and the word Preprocessing will appear in red at the bottom of the application window. You may now use transformation tools to transform the version format into the standard format of the relevant fields. These transformations will be repeated any time the field versions are recognized. Click Stop recording when preprocessing is done.
Training a data source type
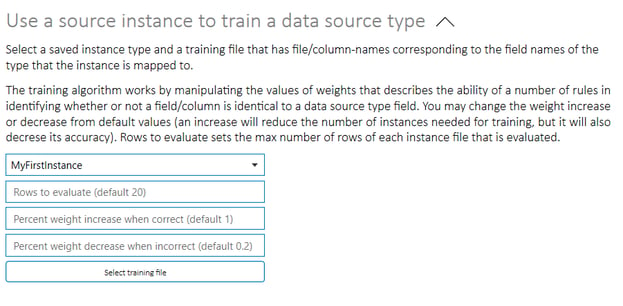
To train a data pattern recognition template to recognize data of the relevant type, use the Use a source instance to train a data source type-settings. Select a source type and load a training file of a type that have been mapped as described above.
The training algorithm works by manipulating the values of weights that describes the ability of a number of rules in identifying whether or not a field or column is identical to a data source type field. It is possible to change the weight increase or decrease from default values. An increase will reduce the number of instances needed for training, but may reduce accuracy. You may also change the number of rows of each source instance to be evaluated from the default value (20).
When an abstract source type (say, the abstract category of an account statement) has been trained on several types of instances of real-world data (i.e., account statements with varying structures from different financial institutions), a never before encountered instance may still be recognized and processed with a relevant workflow.